Große Onlineshops nutzen häufig eine sogenannte Facetten- oder Filternavigation. Für den Kunden ist das eine feine Sache, kann er doch bequem nach der gesuchten Größe oder Farbe filtern. Aus SEO-Sicht ist die Navigation doch eher suboptimal, lassen sich damit doch nahezu unendlich viele URLs bilden. Viele Seiten im Index – ist doch super. Werden manche sicher denken. Ist aber nicht so. Ich möchte dies anhand eines Beispiels aus der Praxis erläutern.
Beim Onlineshop, für den ich arbeite, haben wir die Filternavigation vor einigen Jahren eingeführt. Bereits seit Beginn an hatten wir mit vielen Problemen zu kämpfen und einige Verbesserungen eingeführt, die geholfen haben.
So werden alle URLs, bei denen mehrere Produktmerkmale ausgewählt werden, automatisch auf noindex gesetzt. Das sorgt schon einmal dafür, dass nicht so viele URLs im Google-Index landen. Das ist insofern wichtig, weil beim Filtern sehr viele ähnliche Seiten entstehen. Dazu noch mit dünnem Content. Das ist eher kontraproduktiv, um gute Rankings zu erhalten.
Das alleine reicht jedoch nicht aus, da Google diese URLs trotzdem liest und unnötig Traffic produziert. Die wirklich wichtigen Seiten werden dadurch seltener vom Google-Bot besucht. So haben wir alle Filter-URLs noch maskiert, so dass sie gar nicht als Links erkannt werden. Das hat geholfen, bis wir vor einigen Monaten einen umfangreichen Relaunch hatten.
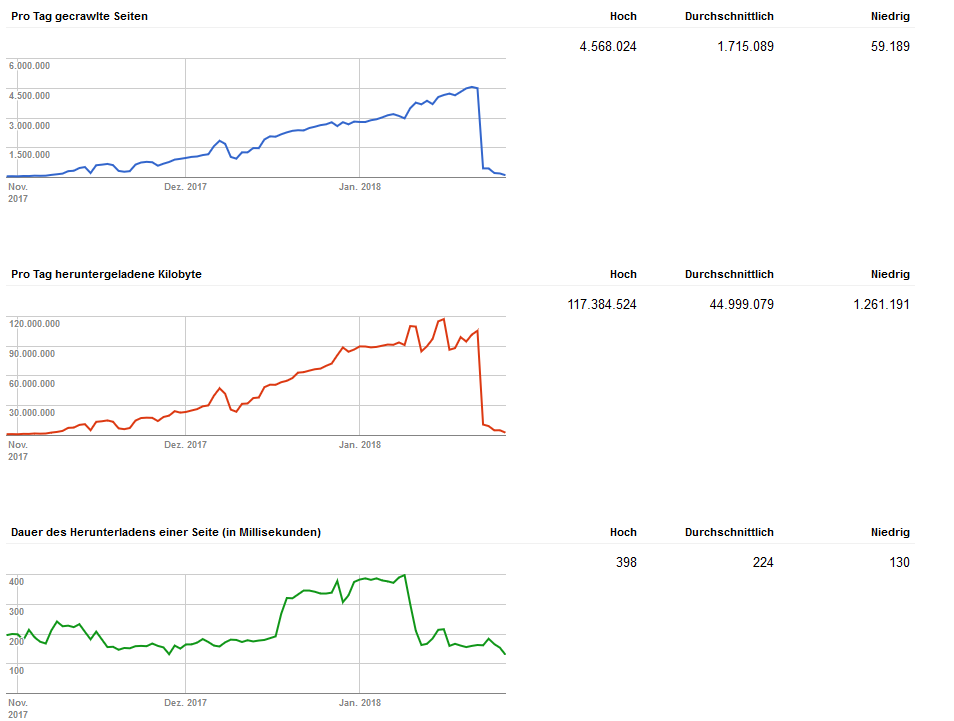
Abb. 1: Crawlverhalten von Google
In der Search-Console sah das dann so aus: Die pro Tag gecrawlten Seiten stiegen stetig an bis zu einem Höchstwert von über 4,5 Millionen Seiten am Tag. Google schickte zuletzt eine ganze Armada an Bots vorbei, die parallel zueinander pro Sekunde zig Seiten auslasen. Entsprechend stieg die pro Tag heruntergeladene Datenmenge stetig an.
Wir haben uns daraufhin die Log-Daten angeschaut und siehe da. Google beschäftigte sich zu über 90 Prozent mit URLs, bei denen mehrere Produktmerkmale miteinander kombiniert werden. Mit Pfaden, die eigentlich auf noindex stehen. Also gar nicht indexiert werden sollen.
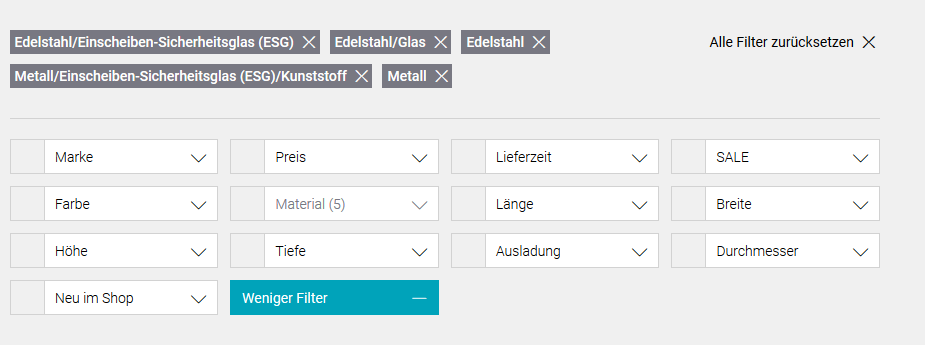
Abb. 2: Filternavigation mit mehreren ausgewählten Produktmerkmalen
Beim Relaunch wurde der Filter aus Kundensicht verbessert. Dieser kann nun die Filter einzeln wegklicken. Wie auf dem Beispiel oben die Materialien. Leider wurde aus SEO-Sicht vergessen, die Links hinter den Kästchen zu verschleiern. Google hatte sein neues Spielfeld gefunden und sich reichlich ausgetobt.
Als unschöner Nebeneffekt stiegen die 404-Fehler in der Search Console in ungeahnte Höhen, da Google durch verfolgen der Links viele weitere Pfade aufdeckte, hinter denen keine Daten liegen. Diese 404-Fehler haben zunächst einmal keinen negativen Effekt auf die Sichtbarkeit der Seite. Es macht es aber schwieriger, die wirklich relevanten 404-Fehler zu identifizieren.
Als Sofortmaßnahme haben wir diese URLs über die robots.txt vom Crawling ausgeschlossen. Dazu reichte eine Zeile mit folgendem Inhalt:
Die Anweisung sagt aus, dass die Suchbots alle URLs ignorieren soll, in denen der Begriff „filter“ sowie mindestens ein Komma stehen. Das Komma bedeutet in diesem Fall, dass zwei Produktmerkmale aus dem Filter kombiniert wurden. Wie im obigen Beispiel die Materialien.
Sofort ging die Anzahl der gecrawlten Seiten drastisch zurück (siehe Abbildung 1). Google hält sich also an die Vorgaben. Im zweiten Schritt werden die URLs verschleiert, so dass sie kein Bot mehr auslesen und ihnen folgen kann. Dann kann der Eintrag in der robots.txt auch wieder entfernt werden.
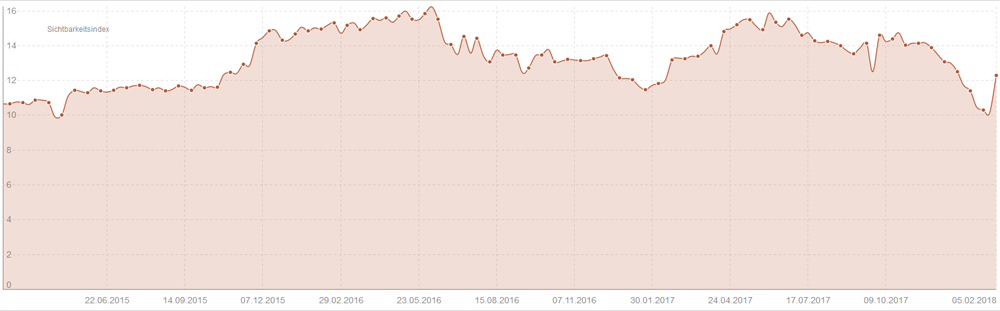
Abb. 3: Sprunghafter Anstieg der Sichtbarkeit bei Sistrix
Rund 10 Tage nachdem wir die Komma-URLs vom Crawling ausgeschlossen haben, vermeldet Sistrix die ersten Erfolge. Der Sichtbarkeitsindex ist sprunghaft gestiegen (siehe Abbildung 3). Unsere Seite wird also bei Google nun wieder sehr viel besser gefunden.
Als Fazit lässt sich aus Sicht eines Texters und SEOs sagen: Wenn die Website nicht rankt, muss das nicht unbedingt an den Inhalten liegen. Wie in diesem Fall, als sich ein eigentlich behobener Fehler nach einem Relaunch wieder eingeschlichen hatte. Also: Immer die Augen auf behalten. Die Search-Console und die Log-Files geben wertvolle Hinweise, was gerade schiefläuft.